Final Writeup
Results
We won fifth overall!
Overview
We developed StandardML-GPU, a Standard ML library and extension that allows a user to
interface with CUDA, and allows Standard ML to take advantage of the computing power of the GPU.
Our library provides an interface between raw CUDA code and Standard ML, an abstraction from
C/CUDA memory management and transfer, and a series of
SEQUENCE data structure
implementations, which will be discussed in the report. Our library acts as a
domain specific language within Standard ML, where a user
is able to express their algorithm in terms of high level operations like scan, tabulate,
and reduce, and is able to beat all other options aside from handwritten CUDA.
Introduction
Sometimes, a few lines of code are worth a thousand words. Below we compare two implementations of parenthesis matching, first using StandardML, and then with our StandardML-GPU library. The algorithms determine whether a sequence of parentheses ( where ( = 1 and ) = -1 ) is matched or not by computing a prefix sum across the input sequence, checking to make sure the element at the end is zero, and the sum never drops below zero along the prefix sum.
Standard ML
fun match_parens s =
let
val (s', last) = Seq.scanIncl (op +) 0 s
in
last = 0 andalso (Seq.reduce Int.min 0 s') >= 0)
end
Standard ML with GPU
fun match_parens s =
let
val (s', last) = GPUSeq.scanIncl Lambdas.add 0 s
in
last = 0 andalso (GPUSeq.reduce Lambdas.min 0 s') >= 0)
end
With almost no changes to the code, other than referencing our new GPUSeq structure and swapping out the higher order function with one from our library’s Lambdas structure, this code will now compile and run on the GPU.
Thus, with little effort, you can expect to see large performance gains from your code! This code greatly outperforms the sequential code generated by the MLton compiler. However, this really isn’t too fair of a test against just a single core!
Comparing Performance of SML Libraries
In parallel to this project, research efforts at CMU have developed a compiler for running Standard ML in parallel on multicore CPUs called the Mlton-Spoonhower compiler. Below we also compare our implementation against the well written, parallel SEQUENCE implementation for that research, running on 72 cores. Note that we had to run these tests on a different machine to get to run with 72 cores.
However, there is an implicit amount of overhead in StandardML that must be maintained which can introduce overhead with large computations. To get a real taste for the acceleration that our library offers, we now compare our run-time speed to that of Thrust, where a computationally comparable algorithm can be written independently. All data collected except the run for the 72 core research compiler were run on the Gates machines with GTX 1080’s.
You can toggle the display of each trace by clicking on its icon in the legend.
As we can see, our performance is competitive across the board, beating out Thrust on larger input sizes, which is a fairer evaluation of our library given the overhead in interfacing with StandardML.
Additionally, even at 72 cores, a single GTX 1080 handily beats out parallel Standard ML on this parentheses matching problem. While there are a lot of low level optimizations that can be made, such as writing sections of the primitives in raw CUDA, or compressing data to use less memory, in terms of performance given ease of use, our library is the obvious choice.
We can use our sequence library to solve a more robust problem : the Maximum Contiguous Subsequence Sum problem. This problem is defined as the following : given a sequence of integers, find the maximum sum out of all possible subsequences of the input sequence. We will solve this problem again using a serial sequence library and our library. You can find the details of the algorithm here.
Here is the Standard ML algorithm :
fun mcss S =
let
val sums = Seq.scanIncl (op +) 0 S
val (mins, _) = Seq.scan Int.min 0 sums
val gains = Seq.zipwith (op -) (sums, mins)
in
Seq.reduce Int.max int_min gains
end
And here is the version using our library :
fun mcss S =
let
val sums = GPUSeq.scanIncl Lambdas.add 0 S
val m_sums = GPUSeq.makeCopy sums
val (mins, _) = GPUSeq.scan Lambdas.min int_max m_sums
val gains = GPUSeq.zipwith Lambdas.sub (sums, mins)
in
GPUSeq.reduce Lambdas.max int_min gains
end
Again, we see with little changes to our code, we can accelerate this problem on the GPU with competitive performace to thrust.
Background
Functional programming naturally describes transformations of data in a declarative manner. Since functional languages are extremely easy for programmers to express algorithmic ideas in, we hope that their code can run fast and efficiently without having to translate their code into another language. Additionally, they should be able to use the same functional programming methodology and see superior performance without drastic changes to their own code in Standard ML.
Functional programs expressed with SEQUENCE
primitives allow for powerful abstractions for algorithm design, and leaves the dirty work of
efficiently implementing these primitives up to the implementer of the library. Primitives like
scan, reduce, filter, etc. are extremely data parallel, and map well to the GPU platform.
However, there previously was no way that functional programmers could use these ideas from a functional
setting, having to resort to using libraries like Thrust in
C to get the same kind of abstraction.
Allowing for an interface between Standard ML and the GPU has several difficulties, which relate to the restricted nature of GPU computation, in contrast to the lack of restrictions in terms of memory management and syntactic constructs of Standard ML. To be specific, the difficulties lie in:
- Providing an intuitive abstraction for memory management for device memory, since Standard ML does not have manual memory management.
- Providing a flexible interface (as much polymorphism and higher order functions as possible) that allows users to write mostly SML, and more functional style programs.
- Implementing very efficient primitives that allow for arbitrary user-defined functions.
- Work around the structure of parallel function programs to allow for more efficient use of hardware.
Abstraction
Throughout our library users do not have to be familiar with any interface to the GPU. By extending the Standard ML library through the Foreign Function Interface, users are able to exploit the built-in function lambdas and SML GPU sequence functions in order to accelerate their workload. In the case that a user is familiar with CUDA or would like to bring an expert in to optimize an important calculation, our interface is easily extendable to allow this.
GPU Arrays
In the structure GPUArray, we define an abstraction for arrays that are hosted on the device. Using this interface,
through methods like initInt or copyIntoIntArray, a user can move between these objects and the built in
Standard ML Array structure to abstract away grungy manual copying,
as well as ensuring that device data is never accessed from the host. A more experienced user can directly
manipulate the data that these arrays point to, and explicitly launch their own more specified kernels if needed.
GPU Sequences
Our GPU Sequences are built on top of these GPU Arrays and are intended to be the main point of usage for the library.
We support a smaller subset of the operations supported by the full
15-210 SEQUENCE Library. Through limitations of
the Foreign Function Interface that Standard ML provides, we must restrict the types of these sequences from purely
polymorphic to integers, floats, and integer tuples.
Implementation
Memory Management
The GPU Array structure has interface calls to CUDA, where we allocate arrays directly on the GPU, and pass around pointers (not revealed to the user) to these arrays on the Standard ML side. Using other functions in the GPU Array structure, we handle copying from and to local arrays on the Standard ML side. We used the type and module system to make memory management feel just like using a standard module, where the only ways to create and manipulate objects is through the interface that the module provides. The key difficulty in this portion of the development was figuring out the intricacies of the Standard ML Foreign Function Interface, and making sure the Standard ML interfaced with CUDA without errors.
Sequence Primitives
Performance Assumptions
The key insight that we made for these sequence operations, as well as the rest of the primitives, was the lack of necessity to maintain persistence of data throughout execution. Most of the time, a user does not need to make a new copy of a 1 billion element array every time it is modified, which must be done in a purely functional runtime. So instead, we decided to relax this constraint when it would interfere with performance significantly. Thus, we perform mutation directly on the sequence given to avoid unnecessary copying. If a user does not want their data directly modified, then they can use our interface to make a copy of their data. To attain good performance, we sadly must do away with persistence often, since a large portion of these primitives are bandwidth bound. Any additional memory operations will just slow the performance down even more.
Map, Tabulate, and Zip
map, tabulate, and zip are all extremely data parallel operations, and as expected their GPU implementations benefited from this.
Reduce
Our efficient implementation of reduce was inspired by this
Nvidia blog post.
The key to our fast implementation of reduce is the __shfl_down intrinsic. __shfl_down allows
for extremely fast in-warp communication - much faster than shared memory. __shfl_down
allows us to replace large shared memory reads and writes with a single instruction that allows
“threads” in a warp to communicate with each other. For example, if we were to execute this code
below, we would see the following behavior in our warp.
int i = threadIdx.x % 32;
int j = __shfl_down(i, 2, 8);
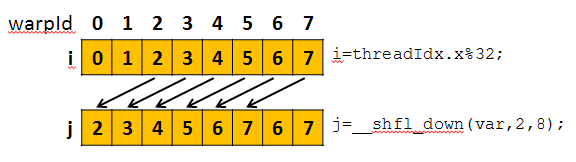
We implement a warp-local reduction by shifting down and combining results by a power of 2 each iteration. At the first level, everything is shifted down 1 row, then 2, then 4 and so on. On the last iteration, the final reduced value for that warp is held by the “thread” at warp index 0.
This intrinsic leads us nicely to a reduce implementation. Our algorithm does the following:
- Allocate an array for partial results whose size is equal to the number of blocks we split our input into.
- For each block, we have each warp compute a warp-local reduction, and store this in a shared array.
- Then we have the first warp do another warp-local reduction over each warp’s stored results.
- Lastly, we launch 1 more kernel, to do the same procedure on each block’s partial reduction.
This reduction performs extremely well beating out thrust by a constant multiple The key to this performance is the
__shfl_downintrinsic. We are able to perform a warp-local reduction in basically 5 steps, as opposed to large amounts of reading and writing into shared memory.
Scan
Our scan implementation is also based upon the __shfl class of intrinsics, this time utilizing
the __shfl_up intrinsic. We can compute a warp-local scan by shuffling the values up the warp,
and combining a “thread’s” current value with the value being sent up to it by the __shfl.
At a glance, this may seem like the classic work inefficient scan algorithm! We cannot lie,
it does follow the same pattern. However, since the data is being transferred to each “thread” in
the warp anyway, we are not saving any computation by only combining certain elements. Because
each “thread” in the warp is a vector unit, they will all be executing the same instructions anyway.
So what seems like a work-inefficient implementation is actually using the hardware well, and not doing
very much extra work. Lastly, the speedup from using __shfl_up as opposed to a shared memory
upsweep and downsweep is worth the few extra addition operations.
Our algorithm for scan mirrors that of reduce :
- Allocate an array for partial results whose size is equal to the number of blocks we split our input into.
- For each block, we have each warp compute a warp-local scan, and store this in a shared array.
- Then we have the first warp do another warp-local scan over each warp’s stored results, and write the block’s partial result into an output array.
- We repeat this blockwise process until we fit the entire scan out into a single block.
We change the algorithm slightly for an exclusive scan, where at the last step we perform a shift on the output array to enforce the exclusion property of the scan.
Our library is very competitive with Thrust.
Filter
Filter is a standard implementation, using a prefix sum and a mapping operation to figure out which elements to keep, and where those elements should go in the output sequence. Due to the good performance of previous primitives, filter performs excellently as well.
Arbitrary Functions
A key part of this project was to make sure that users could provide arbitrary functions to our sequence library, and not be constrained to built-in functions that came with the library. We hoped to be able to let users write inline lambdas in Standard ML for our sequence functions. However, all the CUDA code needs to be pre-compiled separately, which means that users must write their functions in C (sad reacts only). Additionally, we ran into errors getting CUDA cross file linking to work, so we have a very rigid structure for these higher order functions. Internally we represent these higher order functions as function pointers, and the values that the Standard ML code references are just pointer types. Unfortunately, function pointers are not elegantly supported by CUDA. Thus, just to create a usable device function pointer, we must convert a function like this
int my_func(int i){
return 1;
}
to a large chunk of CUDA annotated code like this, as well as import this function into Standard ML.
__device__
int my_func(int i){
return 1;
}
tabulate_fun_int my_func_dev = my_func;
void* gen_my_func(){
tabulate_fun_int local;
cudaMemcpyFromSymbol(&local, my_func_dev, sizeof(tabulate_fun_int));
return (void*) local;
}
However, our goal for the library was that a user without much CUDA knowledge could easily
write their own performant code. So we created a script to automate this process. A user must create a file
within which they have the function they want to write. Then they just invoke the function_gen.py script
in the lib directory and all the CUDA code as well as Standard ML linking is generated! For example
./function_gen.py tabulate_fun_int <infile> funcptrs/user_tabulate_int.h
would read in the function inside <infile>, and generate the code for it inside the header file funcptrs/user_tabulate_int.h, as well as adding it to the lambdas structure which holds all of the int sequence higher order functions.
To handle the interfacing with these higher order functions, we do the loading and importing
in structures like GPUINTLambdas or GPUFLOATLambdas. The user can then reference the functions
they import as values inside these structures.
To give an example of the full process, say the user wanted to create a function to double and increment everything in a sequence they have. The procedure would be as follows :
- Create a file holding the following function
int mapper(int x){
return 2*x + 1;
}
- Run the function generator script above. We use the arguments map_fun_int and the outfile funcptrs/user_map_int.h.
Since this function was a function to be applied on integers, it will be placed in the GPUINTLambdas structure.
val mapped = GPUSeq.map GPUINTLambdas.mapper S
A tradeoff we experienced with function pointers was that they are quite slow! We saw a noticeable performance increase when we replaced all function pointer calls to additions. However, the flexibility of the library was much more worth it than the performance that hard coding additions gave us.
Types and Tuples
Due to the nature of the Foreign Function Interface between Standard ML and C, the liberties
we are allowed to take with typing in Standard ML are no longer there when we try to interface
with C. We were able to implement a strange version of polymorphism in C by making every possible
datatype a void* type, but this introduced a large amount of extra work, as we would then have to
pass around datatype size, and what kind of data was actually being stored. Additionally, this
was very cumbersome from a user perspective, as the syntax was ugly and extremely unusable. For
example, to return a value of type int from a function, a user would have to use
return *(void**)(&retun_value);
We decided it would be better instead to create several implementations of our sequence structures for different commonly used types - integer, floats, and integer tuples.
Fusing
Classically, programs that exhibit behavior like the following are usually bandwidth bound, and require manual fusing by the user.
val s1 = Seq.map (fn x => 2 * x) S
val s2 = Seq.map (fn x => x + 1) s1
val result = Seq.reduce (op * ) 1 s2
This code could have both maps turned into just 1 map, so that data is accessed only once. In the general
case however, it is easier for users to think about their code when they can break up the data accesses
and operations on the structure. With this in mind,
our library supports a powerful feature that allows the user to fuse multiple sequence operations into a
single kernel launch decreasing the overhead and dramatically improving performance. All mapping operations
are evaluated lazily, only applied when the force function is called, or when a primitive that needs the
mapped values, like scan or reduce is called.
Below we have an example of our fusing in action. Our example code will call a series of maps, and then a reduce on the mapped data. Notice how increasing the number of maps before reduction causes more and more overhead for thrust and Standard ML, but the time taken by our library stays relatively constant.
In a less contrived setting, this fusing ability is extremely useful for just allowing programmers to write transformations on data without having to worry about performance issues of those transformations. Being able to fuse even one mapping operation into a reduction can shave a constant off the overall runtime of the program.
We implemented fusing by adjusting how sequences were represented for the structure
FusedINTGPUSequence. Now, these structures also carry around a list of functions
that need to be applied. Whenever a mapping operation is called, a kernel is not
launched. Instead, this function is just pushed onto the list. During any aggregate
operation, like a scan or a reduce, before the data is operated on, all the
functions in the list are immediately applied to the data inside the kernel that is
doing the reduction or the scan. This idea can be extended further in a functional programming
setting, where we can represent sequences with functions, and delay computation as long as possible.
Performance and Analysis
While our primitives beat Thrust, there are better libraries to compare implementations against, such as CUB. Additionally, we can see that while our performance on primitives was better, in a program that used a group of primitives in conjunction with each other, we weren’t able to beat Thrust quite as handily, which means that we can definitely work to pipeline and group operations together better.
Conclusion
Our library enables never before seen performance in SML and brings a new level of deployability to SML. Our use of a GPU limits the scope of usability to those with an NVIDIA GPU in their system, but we feel that modern computers - especially those used to process datasets on billions of elements - are suitably equipped such that this is not a restriction to the end user. CPU based acceleration through MLton had already been attempted and the GPU was necessary for the next order of magnitude increase in performance. Through all of our kernels you can see that our library while interfacing with SML is able to compete and beat thrust which is an excellent benchmark for well implemented GPGPU algorithms. The translation from StandardML to StandardML-GPU is minimally complicated and expandable. As more users implement larger algorithms we can identify common closures that may benefit from new kernels allowing the library to evolve and take advantage of low-level optimizations mentioned before.
Work Distribution
Rohan worked with the StandardML foreign function interface to allow the interoperability between CUDA and SML building the framework from the ground up. After numerous issues with cross file linking he established the rigid library structure for where the elements of the library needed to go to enable compilation. Brandon worked on extending the interface to provide usability such as with tuple types and validation for the existing sequence implementations. Brandon also made all of the cool interactive graphs and is working on providing a concise documentation to enable new users to effectively deploy our library. His goal is to have a set of mature SML examples implemented in StandardML-GPU to show the usefulness and performance across a variety of samples.
Checkpoint
Find our checkpoint write-up here.
Proposal
Find our proposal write-up here.